Continuing from the conclusion of
my last post, I had gotten to the point of testing the LMI’s Interphase SMD 2181 disk controller, but was getting troubling looking diagnostic output:
SDU Monitor version 102
>>/tar/2181 -C
Initializing controller
2181: error 3 test 0 Alarm went off - gave up waiting for IO completion
2181: error 3 test 0 Alarm went off - gave up waiting for IO completion
2181: error 10 test 0 no completion (either ok or error) from iopb status
iopb: cyl=0 head=0 sector=0 (TRACK 0)
87 11 00 00 00 00 00 00 00 00 00 00 10 00 c5 62 00 40 00 00 00 00 c5 3a
My immediate suspicion was that this was truly indicating a real failure with the controller. The “gave up waiting for IO completion” message was the canary in the coal mine here. The way a controller like this communicates with the host processor (in this case the SDU) is via a block of data in memory that the controller reads, this is the “iopb” (likely short for “I/O Program Block”) mentioned in the output above. The iopb contains the command to the controller, the controller executes that command then returns the status of the operation in the same iopb, and may interrupt the host processor to let it know that it’s done so. (More on interrupts later.)
What the above diagnostic failure appears to be indicating is that the SDU is setting up an initialization command in the iopb and waiting for the 2181 to return a result. And it waits. And it waits. And it waits. And then it gives up after a few milliseconds because the response has taken too long: the 2181 is not replying, indicating a hardware problem.
But the absence of any real documentation or instructions for these diagnostics or the 2181 controller itself left open other possibilities. The biggest one was that I did not at that time have an actual disk hooked up to the controller. The “-C” option to the 2181 diagnostic looked like it was supposed to run in the absence of a disk, but that could be an incorrect assumption on my part. It may well be that the 2181 itself requires a disk to be connected in order to be minimally functional, though based on experience with other controllers this seemed to me to be unlikely. But again: no documentation, anything could be possible.
The lack of a disk was a situation I could rectify. The Lambda’s original disk was a
Fujitsu Eagle (model M2351), a monster of a drive storing about 470mb on 10.5″ platters. It drew 600 watts and took up most of the bottom of the cabinet. At the time of this writing I am still trying to hunt one of these drives down. The Eagle used the industry-standard
SMD interface, so in theory another SMD drive could be made to work in its stead. And I had just such a drive lying dormant…
If the Eagle is a monster of a drive, its predecessor, the M2284 is Godzilla. This drive stores 160MB on 14″ platters and draws up to 9.5 Amps while getting those platters spinning at 3,000 RPM. The drive itself occupies the same space as the Eagle so it will fit in the bottom of the Lambda. It has an external power supply that won’t, so it’ll be hanging out the back of the cabinet for awhile. It also has a really cool translucent cover, so you can watch the platters spinning and the heads moving:
 |
| The Fujitsu M2284, freshly installed in the Lambda. |
The drive is significantly smaller in capacity than the Eagle, but it’s enough to test things out with. It also conveniently has the same
geometry as another, later Fujitsu disk that the SDU’s “disksetup” program knows about (the “Micro-169”), which makes setup easy. I’d previously had this drive hooked up to a PDP-11/44 and was working at that time. With any amount of luck, it still is.
Only one thing needed to be modified on the drive to make it compatible with the Lambda — the sector size. As currently configured, the drive is set up to provide 32 sectors per track; the Lambda wants 18 sectors. This sector division is provided by the drive hardware. The physical drive itself provides storage for 20,480 bytes per track. These 20,480 bytes can be divided up into any number of equally sized sectors (up to 128 sectors per track) by setting a bank of
DIP switches inside the drive. Different drive controllers or different operating systems might require a different sector size.
The 32 sector configuration was for a controller that wanted 512-byte sectors — but dividing 20,480 by 32 yields 640. Why 640? Each sector requires a small amount of overhead: among other things there are two timing gaps at the beginning and end of each sector, as well as an address that uniquely identifies the sector, and a
CRCs at the end of the sector. The address allows the controller to verify that the sector it’s reading is the one it’s expecting to get. The CRC allows the controller to confirm that the data that was read was valid.
 |
| What a single sector looks like on the Fujitsu. |
The more sectors you have per track, the more data space you lose to this overhead. The Lambda wants 1024-byte sectors, which means we can fit 18 sectors per track. 20,480 divided by 18 is approximately 1138 bytes — 114 bytes are used per sector as overhead. The configuration of the DIP switches is carefully described in the service manual:
 |
| Everyone got that? There will be a quiz later. No calculators allowed. |
Following the instructions and doing the math here yields: 20,480 / 18 = 1137.7777…, so we truncate to 1137 and add 1, yielding 1138. Then we subtract 1 again (Fujitsu enjoys wasting my time, apparently) and configure the dip switches to add up to 1137. 1137 in binary is 10 001 110 001 (1024 + 64 + 32 + 16 + 1), so switches SW1-1, SW1-5, SW1-6, SW1-7 are turned on, along with SW2-4. Simple as falling off a log!
With that rigamarole completed, I hooked the cables up, powered the drive up and set to loading the Interphase 2181 diagnostic again:
SDU Monitor version 102
>>/tar/2181 -C
Initializing controller
2181: error 3 test 0 Alarm went off - gave up waiting for IO completion
2181: error 3 test 0 Alarm went off - gave up waiting for IO completion
2181: error 10 test 0 no completion (either ok or error) from iopb status
iopb: cyl=0 head=0 sector=0 (TRACK 0)
87 11 00 00 00 00 00 00 00 00 00 00 10 00 c5 62 00 40 00 00 00 00 c5 3a
Darn. Looks like having a drive present wasn’t going to make this issue go away.
About that time, a local friend of mine had chimed in and let me know he had a 2181 controller in his collection. It had been installed in a Sun-1 workstation at some point in its life, and was a slightly different revision. I figured that if nothing else, comparison in behavior between his and mine might shed a bit of light on my issue so I went over to his house to do a (socially distanced) pickup.
Annoyingly, the revisional differences between his 2181 and mine were fairly substantial:

 |
| Two Interphase 2181’s. Can YOU spot the differences? |
You can see the commonality between the two controllers, but there are many differences, especially with regard to configuration jumpers — and since (as I have oft repeated) there is no documentation, I have no idea how to configure the newer board to match the old.
So this is a dead end, the revisional differences are just too great. I did attempt to run diagnostics against the new board, but it simply reported a different set of failures — though at least it was clear that the controller was responding.
Well it was well past the time to start actually thinking about the problem rather than hoping for a deus ex machina to swoop in and save the day. I wasn’t going to find another 2181, and documentation wasn’t about to fall out of the sky. As with my
earlier SDU debugging expedition, it seemed useful to start poking at the 2181’s processor, in this case an Intel 8085. This is an 8-bit processor, an update of the 8080 with a few enhancements. Like with the SDU’s 8088, looking at power, clock and reset signals was a prudent way to start off.
Unlike with the SDU, all three of these looked fine — power was present, the clock was counting out time, and the processor wasn’t being reset. Well, let’s take a look at the pinout of the 8085 and see what else we might be able to look at:
 |
| 8085 pinout, courtesy Wikimedia Commons (https://commons.wikimedia.org/wiki/File:Anschlussbelegung_8085.gif) |
 |
| Oscillation overthruster |
The AD0 through AD7 and A15 pins are the multiplexed address/data bus: When the 8085 is addressing memory, AD0-AD7 plus the A8-A15 pins form the 16-bit memory address; when a read or write takes place, AD0-AD7 contain the 8-bits of data being read or written. Looking for activity on these pins is a good way to see if the CPU is actually running — a running CPU will be accessing and addressing memory constantly — and sure enough, looking with an oscilloscope showed pulsing on these pins.
The TRAP, RST7.5, RST6.5, RST5.5, and INTR signals are used to allow external devices to
interrupt the 8085’s operation and are typically used to let software running on the CPU know that a hardware event has occurred: a transfer has completed or a button was pushed, for example. When such an interrupt occurs, the CPU jumps to a specific memory location (called an interrupt vector) and begins executing code from it (referred to as an interrupt service routine), then returns to where it was before the interrupt happened. If any of these signals were being triggered erroneously it could cause the software running on the CPU to behave badly.
Probing the RST7.5, 6.5 and 5.5 signals revealed a constant 3.5V signal at RST7.5, a logic “1” — something connected to the 8085 was constantly interrupting it! This would result in the CPU running nothing but the interrupt service routine, over and over again. No wonder the controller was unable to respond to the Lambda’s SDU.
Now the question is: what’s connected to the RST7.5 signal? It could potentially come from anywhere, but the most obvious source to check on this controller is one chip, an
Intel 8254 Programmable Interval Timer. As the name suggests, this device can be programmed to provide timing signals — it contains three independent clocks that can be used to provide precise timing for hardware and software events. The outputs of these timers are often connected to interrupt pins on microprocessors, to allow the timers to interrupt running code.
 |
| The Intel 8254 Programmable Interrupt Timer |
And, as it turns out, pin 17 (OUT 2) of the 8254 is directly connected to pin 7 (RST7.5) of the 8085. OUT 2 is the data output for the third counter, and goes high (logic “1”) when that timer elapses. Based on what I’m seeing on the oscilloscope, this signal is stuck high, likely indicating that the 8254 is faulty. Fortunately it’s socketed, so it’s easy to test that theory. I simply swapped the 8254s between my controller and the one I’m borrowing from my friend and…
Success! Probing RST7.5 on the 8085 now shows a logic “0”, the CPU is no longer constantly being pestered by a broken interval timer and is off and running. The diagnostic LEDs on the board reflect this change in behavior — now only one is lit, instead of both. This may still indicate a fault, but it’s at least a different fault, and that’s always exciting.
Well, the controller is possibly fixed, and I already have a disk hooked up and spinning… let’s go for broke here and see if we can’t format the sucker. The “-tvsFD” flags tell the controller to format and test the drive, doing a one-pass verify after formatting. Here’s a shaky, vertically oriented video (sorry) of the diagnostic in action:
And here’s the log of the output:
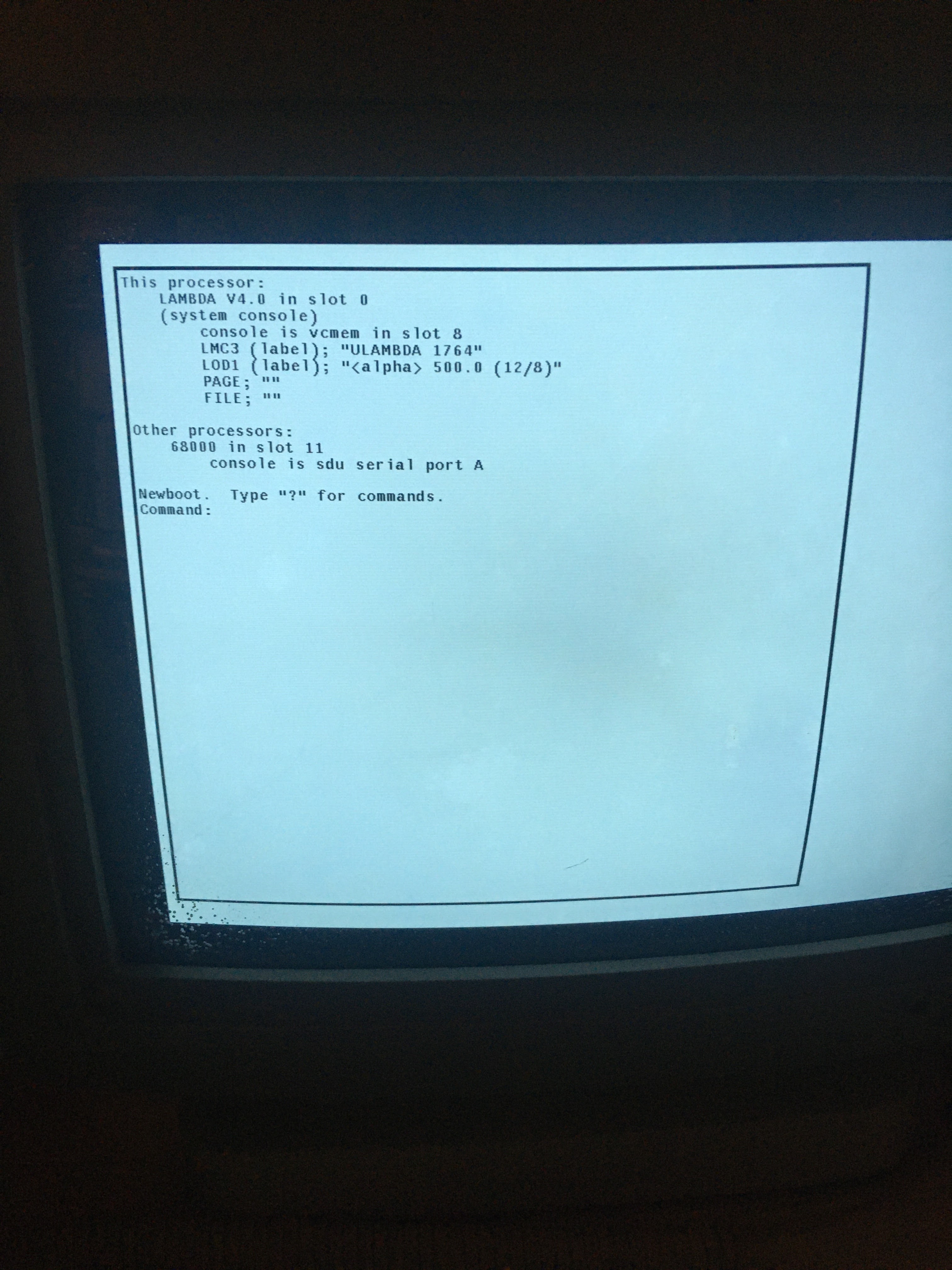
SDU Monitor version 102
>> reset
>> disksetup
What kind of disk do you have?
Select one of { eagle cdc-515 t-302 micro-169 cdc-9766 }: micro-169
>> /tar/2181 -tvsFD
Initializing controller
2181: status disk area tested is from cyl 0 track 0 to cyl 822 track 9
2181: status format the tracks
Doing normal one-pass format ...
2181:at test 0 test reset passed
2181: test 1 test restore passed
2181: test 2 test interrupt passed
failedginning of cyl 159 ... at beginning of cyl 0 ...
2181: error 18 test 4 header read shows a seek error
iopb: cyl=0 head=0 sector=0 (TRACK 0)
00 00 82 12 00 00 00 00 00 00 00 12 10 00 c5 62 00 40 00 00 00 00 c5 3a
2181: error 18 test 4 header read shows a seek error
The 1 new bad tracks are:...
bad: track 1591; cyl=159 head=1
... mapped to track 8229; cyl=822 head=9
There were 1 new bad tracks
Number of usable tracks is 8228 (822 cyls).
(creating block-10 mini-label)
Disk is micro-169
2181: test 5 read random sectors in range passed
2181: status read 500 random sectors
2181: test 6 write random sectors in range passed
2181: status write to 500 random sectors
2181: test 8 muliple sector test passed
2181: test 9 iopb linking test passed
2181: test 10 bus-width test passed
2181: test 0 test reset 0 errors
2181: test 1 test restore 0 errors
2181: test 2 test interrupt 0 errors
2181: test 4 track verify 2 errors
2181: test 5 read random sectors in range 0 errors
2181: test 6 write random sectors in range 0 errors
2181: test 8 muliple sector test 0 errors
2181: test 9 iopb linking test 0 errors
2181: test 10 bus-width test 0 errors
>>
And some video of the drive doing its thing during the verification pass:
As the log indicates, one bad track was found. This is normal — there is no such thing as a perfect drive (modern drives, both spinning rust and SSD have embedded controllers that automatically remap bad sectors from a set of spares, providing the illusion of a flawless disk). Drives in the era of this Fujitsu actually came with a long list of defects (the “defect map”) from the factory. A longer verification phase would likely have revealed more bad spots on the disk.
Holy cow. I have a working disk controller. And a working disk. And a working tape drive. Can a running system be far off? Find out next time!









































{kind=link}